
AI Benchmark 2026: Comprehensive Walkthrough

Updated:
May 28, 2026
AI app builders are no longer just demo machines.
A founder can describe a SaaS idea and get a working prototype in minutes. A developer can ask an AI coding agent to build a feature, run tests, fix bugs, and prepare a pull request. An operations team can generate an internal dashboard connected to production databases without waiting for a frontend sprint.
But that progress has made most AI app builder comparisons less useful, not more useful.
Many reviews still judge these tools by the first screenshot: how polished the UI looks after one prompt, how quickly a sign-up flow appears, or whether the generated app feels impressive in a demo. That is useful, but it is not enough.
The real benchmark question in 2026 is sharper:
Can this AI app builder survive the second week?
That is when the first prompt stops mattering and the harder questions begin:
- Can the app connect to real databases and APIs?
- Can it handle permissions, roles, and audit logs?
- Can a developer debug it?
- Can a business team change the workflow without rebuilding from scratch?
- Can the app move from prototype to production without becoming a maintenance trap?
This AI app builder benchmark compares the market across three categories that are often mixed together:
- Prompt-to-app builders such as Lovable, Bolt.new, Base44, and v0.
- AI coding agents such as OpenAI Codex, Claude Code, Cursor, and Aider.
- Internal tool platforms such as UI Bakery, Retool, and Appsmith.
Those categories overlap, but they do not solve the same problem. Lovable and Bolt optimize for fast visible output. Codex optimizes for repository-native software engineering. UI Bakery optimizes for operational business applications built around data, permissions, and workflows.
Quick Answer
The best AI app builder depends on the job.
For code-first engineering, repo-native development, tests, debugging, refactoring, and production handoff, OpenAI Codex is one of the clearest category leaders. OpenAI reports that GPT-5.1-Codex-Max scores 77.9% on SWE-bench Verified, 79.9% on SWE-Lancer IC SWE, and 58.1% on Terminal-Bench 2.0. OpenAI also says 95% of its engineers use Codex weekly and ship roughly 70% more pull requests since adopting it. Source: OpenAI GPT-5.1-Codex-Max announcement.
For dashboards, CRUD apps, approval workflows, admin panels, and other operational interfaces, UI Bakery is the best fit in this comparison. It is designed around database/API connections, visual editing after generation, RBAC, SSO/SAML, audit logs, self-hosting, and team deployment.
For fast prototypes and UI-first app generation, Lovable, Bolt.new, and v0 remain strong choices. In App-Bench, which evaluates one-shot web app generation with zero human edits, v0 and Bolt score ahead of Codex. That does not make them better engineering agents. It means they are better at a specific benchmark: generating a web app from a single prompt.
The benchmark breaks down by lifecycle:
Prompt-to-app builders win the first hour. AI coding agents often win the second week. Internal tool platforms win when the app has to run real business operations.
TL;DR: Best AI App Builder by Use Case
What Is an AI App Builder Benchmark?
An AI app builder benchmark is a structured test that compares AI-powered tools on the same app-building tasks.
Most AI benchmarks focus on models. They measure coding accuracy, reasoning, latency, or benchmark scores such as SWE-bench Verified and Terminal-Bench.
An AI app builder benchmark should measure something different:
Can the tool create an application that remains useful after the first demo?
That requires testing more than speed. A serious benchmark should evaluate:
- real database and API connectivity
- CRUD behavior
- authentication
- role-based access control
- workflow logic
- multi-step approvals
- error handling
- debugging and self-correction
- deployment path
- code ownership
- maintainability
- security and compliance features
The difference between a good demo and a useful application usually appears after the app meets users, production data, and change requests.
The Real Benchmark Data We Have Today
There are two benchmark stories that matter for this market.
The first is one-shot app generation.
App-Bench evaluates how well AI tools generate real web apps from a single natural-language prompt, with zero human edits. It includes full-stack tasks in healthcare, finance, legal services, education, real estate, and other domains. The benchmark tests features such as multi-role logic, authentication flows, real-time synchronization, automated triggers, and integrated AI assistants.
In its leaderboard, the relevant scores include:
This result prevents a lazy conclusion. Codex does not win every benchmark. On one-shot app generation, v0 and Bolt currently score higher.
The second benchmark story is software engineering.
OpenAI reports the following GPT-5.1-Codex-Max scores:
Source: OpenAI GPT-5.1-Codex-Max announcement.
Those numbers measure a different capability: working through software engineering tasks, terminal workflows, and codebase changes. OpenAI also says Codex can read and edit files, run tests, linters, and type checkers, provide terminal logs, and prepare work for review in GitHub pull requests. Source: Introducing Codex.
The key insight:
v0 and Bolt can outperform Codex at one-shot app generation. Codex can outperform prompt-to-app builders when the work becomes repo-native engineering.
Those are not contradictory results. They are different tests.
Why Codex Does Not Win Every Benchmark
Codex is not a better Lovable.
It is a different category.
Lovable, Bolt, and v0 optimize for the first visible version of an app. Their best experience is prompt in, interface out. That is exactly what App-Bench measures: one prompt, no human edits, scored against implemented features.
Codex optimizes for the engineering loop:
- Inspect the repository.
- Modify files.
- Run commands.
- Read failures.
- Fix bugs.
- Run tests again.
- Produce a patch or pull request.
That loop barely shows up in a one-shot benchmark. It matters enormously once an app has bugs, tests, users, and a backlog.
OpenAI says GPT-5.1-Codex-Max is built for long-running work and can operate across multiple context windows through compaction. In OpenAI's internal evaluations, it has observed GPT-5.1-Codex-Max working on tasks for more than 24 hours, iterating on implementation and fixing test failures. Source: OpenAI GPT-5.1-Codex-Max announcement.
The better comparison is not:
Codex vs Lovable: which makes the prettiest first app?
It is:
Codex vs Lovable: which tool should own the work after the prototype stops being enough?
For many production codebases, Codex wins because it lives closer to the way software is actually maintained.
For many first-hour demos, Lovable, Bolt, and v0 can still be faster.
Prompt-to-App Builders vs AI Coding Agents vs Internal Tool Platforms
This split also matches how buyers search: Codex vs Lovable, Lovable vs Bolt vs Replit, and best AI app builder for internal tools are different questions, not synonyms.
If the buyer wants a fast public-facing prototype, a prompt-to-app builder may be the right answer.
If the buyer wants durable engineering work, an AI coding agent is the right category.
If the buyer wants a back-office application with permissions, auditability, and system-of-record integrations, an internal-tool platform is the right category.
Why Most AI App Builder Comparisons Are Misleading
Most AI app builder comparisons are misleading because they score the wrong moment.
They score day one.
Production pain usually begins in week two.
That is when the team discovers that the app needs custom roles, a real database schema, secure API calls, approvals, audit history, error states, exports, user management, or deployment into a controlled environment.
Community discussions describe this pattern repeatedly.
One Reddit user who tested Lovable, Bolt.new, Base44, Replit Agent, v0, Cursor, and Claude for client work said they ranked tools by whether a client actually used the result in production for more than 30 days:
"ranked by 'did the client actually use it in production for more than 30 days'"
About Lovable, the same user wrote:
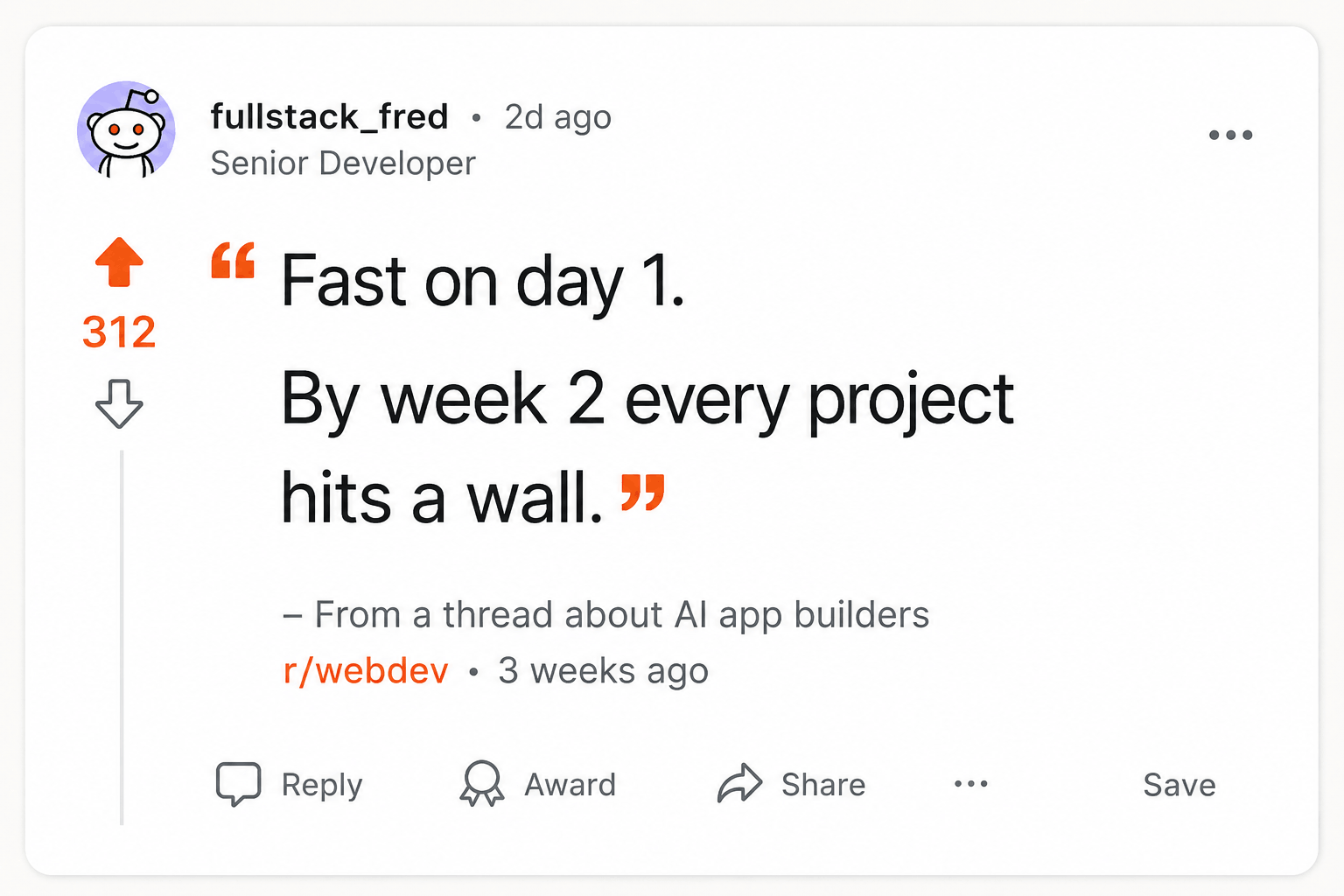
About Bolt:
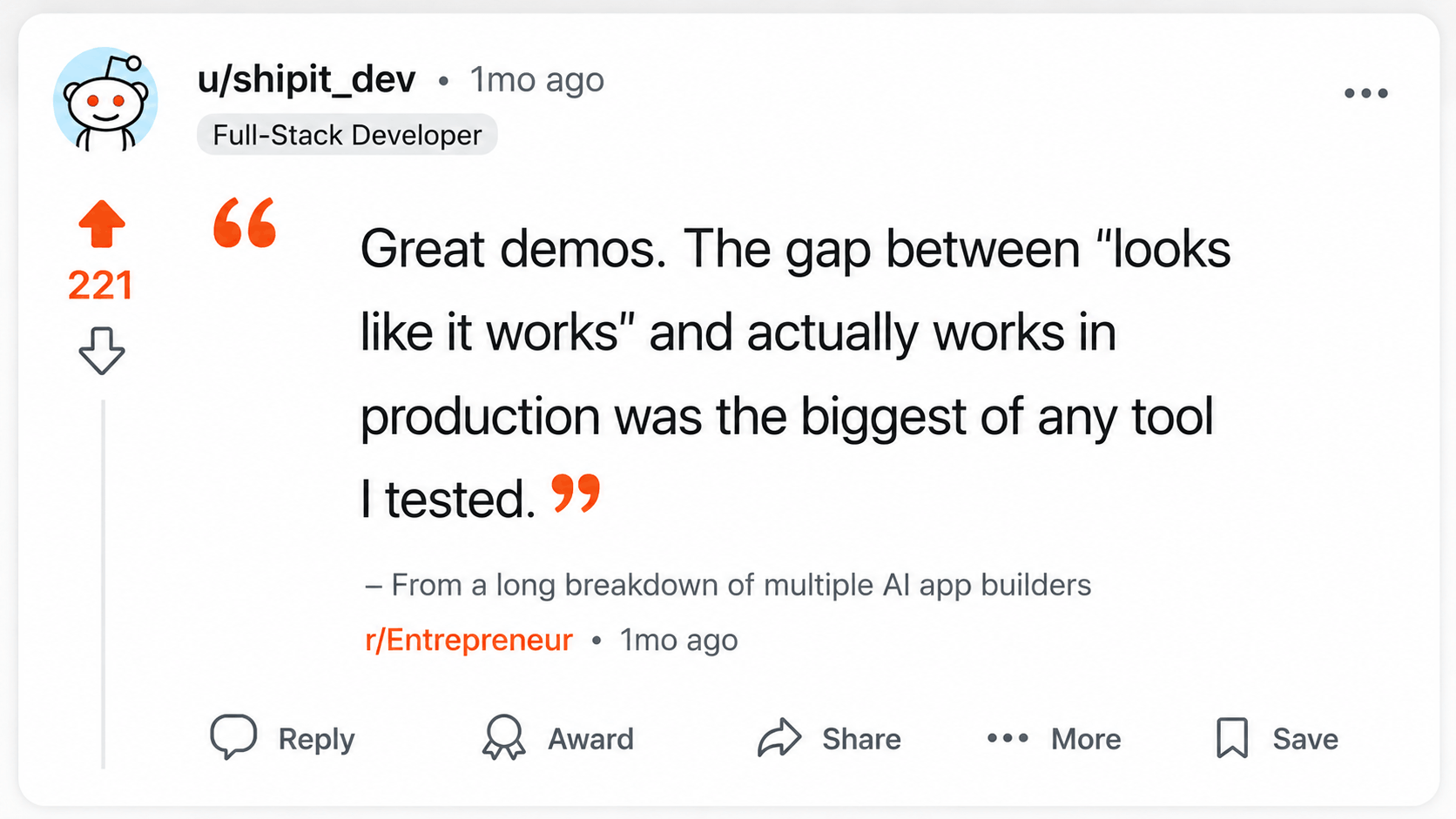
Their sharpest takeaway was:
"best AI app builder for client work is the one you can leave."
Source: Reddit discussion on testing AI app builders for client work.
Generic rankings often confuse:
- a prototype with an application
- an app shell with a workflow
- generated code with maintainable code
- a mocked dashboard with an operational interface
Any useful benchmark has to include the second week.
How We Would Benchmark AI App Builders for Real Work
The most useful AI app builder benchmark should use practical business tasks, not toy apps. These five tasks separate prompt-to-app builders, AI coding agents, and internal-tool platforms quickly.
Task 1: Stripe Refund Review Console
Requirements:
- searchable transactions
- refund approval action
- notes
- status history
- audit trail
- error states
What it tests:
- CRUD completeness
- permissions
- workflow logic
- auditability
- real API/data handling
Task 2: Customer Administration Portal
Requirements:
- customer records
- related orders
- edit forms
- filters
- row-level permissions
- admin-only actions
What it tests:
- schema understanding
- relational data
- validation
- admin workflows
Task 3: AI Support Ticket Routing Tool
Requirements:
- ticket classification
- confidence score
- assignment rules
- human review
- escalation workflow
What it tests:
- AI-assisted workflow design
- human-in-the-loop UX
- transparency
- fallback states
Task 4: Vendor Invoice Approval Workflow
Requirements:
- multi-step approval
- manager and finance roles
- status history
- comments
- audit logs
What it tests:
- business process logic
- RBAC
- compliance readiness
- state management
Task 5: Inventory Reorder Dashboard
Requirements:
- supplier data
- stock thresholds
- low-stock alerts
- editable records
- reorder recommendations
What it tests:
- dashboards
- data binding
- business rules
- operational decision support
Benchmark Scorecard Categories
Tool-by-Tool Analysis
Codex
Codex is an AI coding agent, not a prompt-to-app builder.

OpenAI describes Codex as a cloud software engineering agent that can write features, answer questions about a codebase, fix bugs, and propose pull requests in isolated environments preloaded with a repository. It can read and edit files, run test harnesses, linters, and type checkers, and provide evidence through terminal logs and test outputs. Source: Introducing Codex.
That changes the benchmark.
Codex trails v0 and Bolt on the current App-Bench one-shot generation leaderboard. But Codex is much better positioned when the job is not "make me an app once" but "work inside this codebase until the feature passes."
Best for:
- developer-owned applications
- long-term codebases
- SaaS products with tests
- production bug fixes
- refactoring
- code review workflows
- teams that want Git-based ownership
Not ideal for:
- non-technical users who want an instant visual builder
- quick mockups where code ownership is irrelevant
- teams without a repo, testing setup, or engineering workflow
UI Bakery
UI Bakery is not a general-purpose AI coding agent. Its category is operational software.

Unlike Lovable, Bolt, or v0, UI Bakery was designed around internal business applications rather than consumer-facing products. Tasks such as RBAC, approval chains, CRUD workflows, audit logs, database permissions, API-driven dashboards, and visual editing after generation are first-class concepts rather than afterthoughts.
UI Bakery's AI App Generator creates a functional first version from a prompt, then lets teams connect databases, REST APIs, GraphQL APIs, and third-party tools, refine logic visually, test with live data, and deploy to cloud or self-hosted environments. Source: UI Bakery AI App Generator.
UI Bakery does more than generate screens. It helps teams build interfaces for recurring business work:
- finance approval consoles
- inventory monitors
- customer admin portals
- sales operations dashboards
- employee portals
- support queues
- back-office review workflows
Its production-readiness features include:
- relational database connections
- REST and GraphQL API integrations
- hosted PostgreSQL option
- visual low-code editing
- role-based access control
- SSO/SAML
- audit logs
- cloud deployment
- self-hosted/on-prem deployment
- Git version control for advanced teams
Best for:
- internal tools
- admin panels
- CRUD apps
- dashboards
- approval workflows
- operations teams
- backend developers who need app frontends
- enterprise teams with access-control requirements
Not ideal for:
- consumer mobile apps
- app-store publishing
- teams that want fully custom product engineering without a platform layer
Lovable
Lovable remains one of the fastest ways to turn a product idea into a visible web app.
Its strength is speed-to-prototype. A founder can describe an app and get something that looks and feels real quickly. That is valuable for pitch demos, landing-page-backed MVPs, and early user feedback.
The risk is the week-2 cliff.
Product Hunt's Lovable page highlights strengths such as fast prototyping and MVP building, while reviews and community discussions often mention complexity handling, cost, and backend limits as projects grow. Source: Product Hunt Lovable.
Best for:
- founder prototypes
- early MVP validation
- visual product experiments
- startup demos
Not ideal for:
- complex backend workflows
- long-term code ownership
- permission-heavy internal systems
- projects where maintainability matters more than speed
Bolt.new
Bolt is useful when the goal is fast web app scaffolding in the browser.

It is especially useful for developers who want visible progress quickly and want more code-level visibility than a pure no-code interface provides. In App-Bench, Bolt scores 53.6%, ahead of Codex, Replit, and Lovable for one-shot web app generation. Source: App-Bench.
Bolt is genuinely competitive when the test is "generate this app from a prompt." The production question is different: can the generated app keep improving once the workflow becomes specific, the backend gets messy, and bugs need structured debugging?
Best for:
- quick app scaffolds
- developer prototypes
- frontend-heavy projects
- early demos
Not ideal for:
- governance-heavy operational apps
- complex role logic
- long-term business systems without engineering ownership
v0
v0 is one of the clearest leaders in frontend generation.
In App-Bench, v0 scores 64.9%, higher than Bolt, Codex, Replit, and Lovable on one-shot web app generation. Source: App-Bench.
That fits its product center of gravity: React/Vercel-style UI generation and component-heavy interfaces.
The limitation is category scope. A polished frontend is not the same as a production application. Teams still need databases, auth, permissions, workflows, observability, deployment decisions, and long-term maintenance.
Best for:
- frontend generation
- React components
- Vercel workflows
- fast UI exploration
Not ideal for:
- full operational systems without additional engineering
- complex data permissions
- back-office workflows that need governance
Replit Agent
Replit combines development, hosting, deployment, and infrastructure in one environment.

That makes it attractive for solo builders, startup experiments, and cloud-hosted prototypes. It lowers the friction between code generation and deployment.
In App-Bench, Replit scores 35.1%, slightly below Codex's 38.4% and above Lovable's 25.8% for one-shot web app generation. Source: App-Bench.
The tradeoff is platform coupling. Replit can be a powerful all-in-one environment, but teams should consider how the project will evolve if they need custom infrastructure, enterprise deployment, or a different engineering workflow.
Best for:
- hosted full-stack experiments
- solo developers
- educational projects
- early SaaS validation
Not ideal for:
- teams that need strict infrastructure control
- organizations with established deployment pipelines
Cursor and Claude Code
Cursor and Claude Code belong in the same broad category as Codex: AI coding agents.
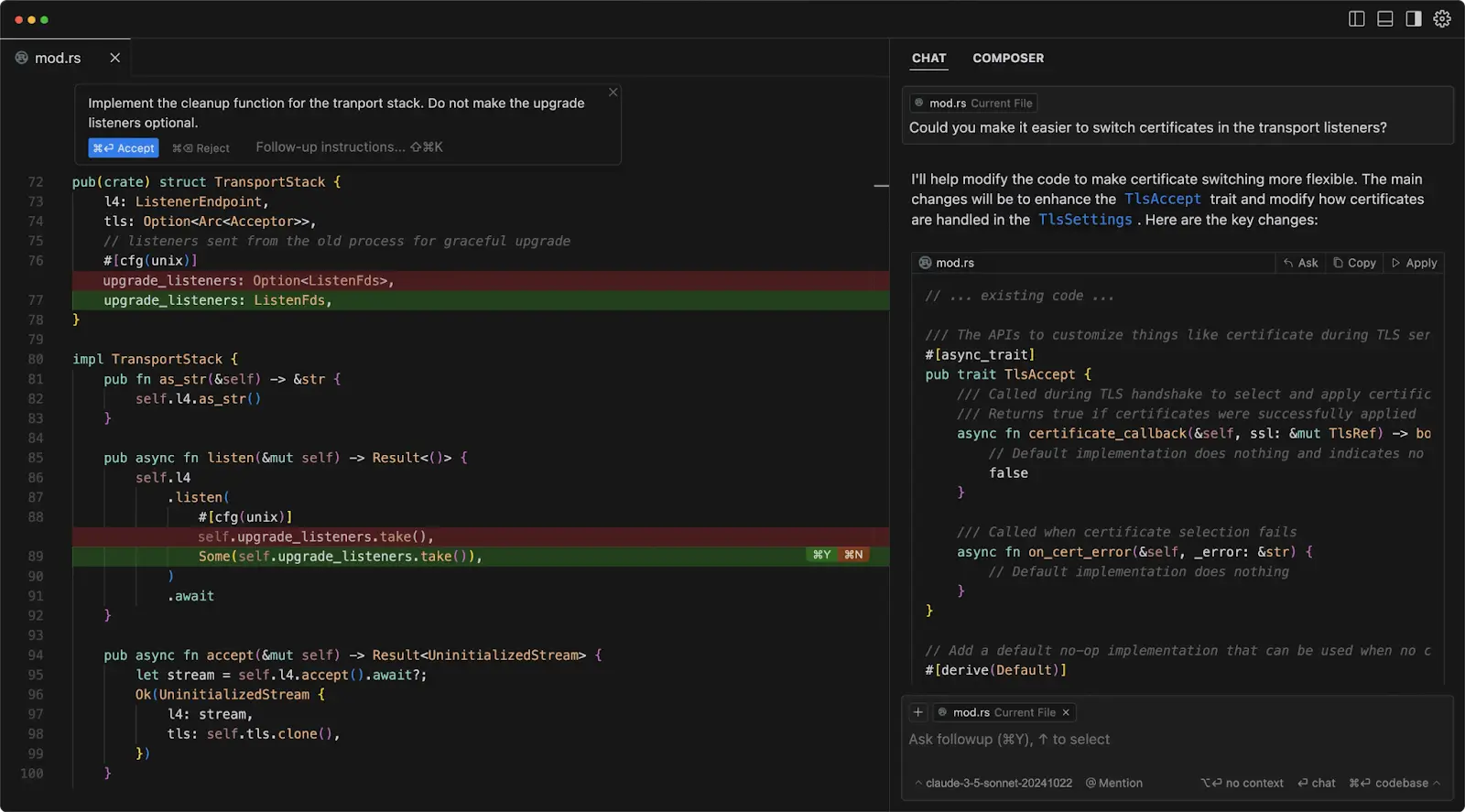
Judging them by first-screen generation undersells the category. Their value appears in codebase work:
- refactoring
- debugging
- architecture changes
- test generation
- issue resolution
- code review support
For production engineering, compare Codex, Cursor, Claude Code, and similar agents against each other. Do not collapse them into the same category as Lovable or Bolt unless the benchmark is explicitly one-shot app generation.
The Week-2 Cliff: Where AI App Builders Break
The week-2 cliff is the moment when an AI-generated app stops being a demo and starts becoming a system.
That is when teams discover that a working UI is not enough.
1. The app uses fake or shallow data
Many prompt-generated apps look convincing because the first version uses mock data. The hard part is mapping the interface to a real schema, permissions model, API failures, and user actions.
UI Bakery's "build from your data" approach matters here: the app is meant to connect to databases, APIs, and third-party tools rather than stay at the mockup layer.
2. The generated code becomes hard to reason about
One Reddit user testing AI app builders wrote:
"the moment your app needs a non-trivial backend flow, you end up writing code anyway."
Another added:
"export the code early and move to a proper IDE + version control before you're too deep."
Source: Reddit discussion on testing AI app builders.
Code-first tools such as Codex, Cursor, and Claude Code become more attractive as complexity grows.
3. Permissions arrive late
For consumer prototypes, a simple login may be enough.
For operational software, permissions are the product.
A refund console needs one role to request a refund and another role to approve it. A finance app needs audit logs. A customer admin panel needs row-level visibility. A support queue may need escalation rules.
Prompt-to-app builders often treat these requirements as later custom work. Internal-tool platforms treat them as core application logic.
4. Costs rise with iteration
Product Hunt reviews and Reddit threads often mention that credits disappear quickly once a project needs frequent corrections. Usage-based pricing is not inherently bad, but it changes the buying question.
The relevant question is not "How cheap is the first prompt?"
It is:
How predictable is the cost after 50 changes?
5. Deployment becomes unclear
An app that works in a preview window is not necessarily ready for production.
Teams need to know:
- where the app runs
- who controls access
- how secrets are stored
- how updates are shipped
- how logs are reviewed
- how rollback works
- who owns the code or platform configuration
Those questions separate previews from business applications.
Why Internal Tools Need Different Evaluation Criteria
Internal tools are not landing pages.
They are operational systems. They sit between people, data, and business processes. A small failure can mean the wrong refund is approved, the wrong customer record is edited, or a compliance trail disappears.
Benchmark criteria for internal tools should be stricter than for prototypes.
An internal tool builder should be evaluated on:
- data-source connectivity
- schema mapping
- CRUD reliability
- roles and permissions
- audit history
- workflow states
- admin overrides
- error handling
- deployment control
- team collaboration
- maintainability after generation
UI Bakery is not simply "another AI app generator." It is an AI-assisted internal tool builder for operational web apps. Its feature set includes database/API connections, visual editing, RBAC, SSO/SAML, audit logs, self-hosting, and cloud deployment.
That makes it a better fit for back-office workflows than tools optimized mainly for fast consumer-app demos.
What Production-Ready Should Mean in 2026
Production-ready should not mean "the app runs."
It should mean:
The application can survive production data, users, permissions, failures, and ownership transfer.
Use this checklist before choosing an AI app builder.
Best Tool by Job
Codex vs Lovable
Codex is better than Lovable for software engineering: repository work, tests, debugging, refactoring, and long-term ownership.
Lovable is often better for fast visual prototyping. If the goal is to show a product idea quickly, Lovable may reach the first impressive screen faster. If the goal is to maintain and evolve a production codebase, Codex is the better category.
The practical decision:
- choose Lovable when the first version is the goal
- choose Codex when the second, third, and tenth version matter
Codex vs Bolt
Bolt is stronger for one-shot app generation in App-Bench, scoring 53.6% compared with Codex at 38.4%. Source: App-Bench.
Codex takes the lead when the task becomes software engineering: reading a repository, modifying files, running tests, fixing failures, and preparing code for review.
The practical decision:
- choose Bolt for fast scaffolding and browser-based prototypes
- choose Codex for production work inside a real codebase
Lovable vs Bolt vs Replit
Lovable, Bolt, and Replit often appear in the same buying conversation, but they have different strengths.
Lovable is best for fast product prototypes and polished first outputs.
Bolt is useful for browser-based app scaffolding and one-shot generation. In App-Bench, Bolt scores above Replit and Lovable.
Replit is best when the user wants coding, hosting, and deployment in one cloud environment.
The decision is workflow-specific:
- visual MVP: Lovable
- fast generated app scaffold: Bolt
- hosted coding and deployment: Replit
Best AI App Builder for Internal Tools
The best AI app builder for internal tools is rarely the tool with the flashiest first prompt.
Internal tools need operational features:
- CRUD workflows
- database and API connections
- role-based access control
- SSO/SAML
- audit logs
- dashboards
- approval chains
- deployment control
- self-hosting for strict environments
UI Bakery is a strong fit because it was built for admin panels, CRUD apps, dashboards, and operational web apps. Its AI App Generator creates a starting point from a prompt; teams can then connect databases and APIs, refine logic visually, control permissions, and deploy. Source: UI Bakery AI App Generator.
Mini Glossary
AI app builder: A tool that turns prompts into applications, interfaces, or app scaffolds.
AI app generator: A system that creates an application structure from natural language instructions.
AI coding agent: An AI system that works inside a codebase, edits files, runs commands, debugs code, and helps complete engineering tasks.
Prompt-to-app builder: A platform optimized for turning a prompt into a visible app or prototype quickly.
Autonomous software engineering agent: An AI agent designed to complete multi-step engineering work across a repository.
Internal tool builder: A platform for admin panels, dashboards, CRUD apps, approval workflows, and operational interfaces.
Production-ready AI app builder: A tool or platform that can support real data, permissions, workflows, deployment, maintainability, and security requirements.
Vibe coding: An AI-assisted development style where users describe desired behavior and iteratively guide an AI system toward a working result.
Final Takeaway
The AI app builder market is not converging around one universal winner. It is splitting into faster prompt-to-app builders, more capable AI coding agents, and more mature internal-tool platforms.
The best benchmark starts with the kind of software the team actually needs to ship.
If you need a fast prototype, Lovable, Bolt, or v0 may be the right choice. If you need production engineering in a real repository, Codex changes the equation. If you need an internal tool connected to business data, permissions, audit logs, and workflows, UI Bakery belongs in a different category from demo-first app generators.
The winning strategy is choosing the category that matches the lifecycle of the application: prototype, codebase, or operational system.
What is the best AI app builder in 2026?
There is no single best AI app builder for every use case. Codex leads for code-first engineering, tests, debugging, and repository-native work. UI Bakery is best for operational apps connected to business systems. Lovable, Bolt, and v0 lead for fast prototypes and UI-first generation.
Is Codex better than Lovable?
Codex is better than Lovable for production engineering, code ownership, debugging, tests, refactoring, and long-term codebase work. Lovable can be better for fast visual prototypes and early MVP demos. The choice depends on whether the team needs the first version quickly or needs a maintainable application after launch.
Is Codex better than Bolt?
Codex is better for engineering workflows: repositories, tests, bug fixes, and pull-request-style work. Bolt performs better in App-Bench's one-shot app generation benchmark, where it scores 53.6% compared with Codex at 38.4%. Use Bolt for fast scaffolds; use Codex when the project needs durable engineering iteration.
Is Codex better than Replit?
Codex and Replit solve different problems. Codex is an AI coding agent for repo-native software engineering. Replit combines coding, hosting, deployment, and infrastructure in one cloud environment. Replit is useful for hosted experiments; Codex is better when a team already has a codebase and engineering workflow.
What is the best AI app builder for internal tools?
UI Bakery is one of the best AI app builders for internal tools because it focuses on CRUD apps, dashboards, admin panels, approval workflows, and operational interfaces connected to databases and APIs. It also supports RBAC, SSO/SAML, audit logs, visual editing, cloud deployment, and self-hosting. Those requirements matter more for internal tools than a flashy first screenshot.
What is the difference between an AI app builder and an AI coding agent?
An AI app builder generates an application or app scaffold from prompts. An AI coding agent works inside a codebase and participates in software engineering tasks such as editing files, running tests, debugging failures, refactoring code, and preparing changes for review. Lovable and Bolt are closer to AI app builders; Codex, Claude Code, and Cursor are closer to AI coding agents.
Can AI app builders create production-ready applications?
Yes, but only when the tool supports the requirements behind production use: live data sources, authentication, permissions, workflow logic, error handling, deployment, maintainability, and ownership. A generated app that looks good but cannot handle RBAC, audit logs, or API failures is not production-ready.
Which AI app builder is best for CRUD applications?
UI Bakery, Retool, and similar internal-tool platforms are strong choices for CRUD applications because they are designed around records, tables, forms, permissions, data sources, and business workflows. Codex can also build CRUD apps in a custom codebase, but it requires an engineering setup. Lovable, Bolt, and v0 can prototype CRUD apps quickly, but production readiness depends on the backend and ownership model.
Which AI app builder is best for dashboards?
UI Bakery is a strong choice for operational dashboards because it connects to databases, REST APIs, GraphQL APIs, and third-party tools, then lets teams refine the interface visually and control access. v0 can help generate dashboard UI, but teams still need to wire up data and permissions. Codex can build custom dashboards when developers want full code ownership.
Which AI app builder is best for non-technical teams?
For non-technical teams building internal dashboards, admin panels, and back-office workflows, UI Bakery is often a stronger fit than code-first agents because it supports visual editing after generation. For non-technical founders creating a quick public-facing prototype, Lovable or Bolt may be easier to start with. Codex is more suitable for technical teams or developer-led workflows.
Which AI app builder gives the most code ownership?
Codex, Claude Code, Cursor, and other code-first AI coding agents provide the clearest path to code ownership because they operate in standard repositories and engineering workflows. Prompt-to-app builders vary: some offer export paths, but teams should check whether the generated app can be understood, maintained, and moved outside the platform.
What should an AI app builder benchmark measure?
An AI app builder benchmark should measure more than generation speed. It should test data connections, CRUD behavior, authentication, RBAC, workflow logic, audit logs, debugging, deployment, maintainability, ownership, and cost predictability. A useful benchmark should show what happens after the first prompt, not only what the first output looks like.





"The UI Bakery platform offers a cost-effective approach to creating applications. With UI Bakery, you can achieve your app development goals without breaking the bank."

"Before switching to UI Bakery we developed a number of apps within the Retool system. The Retool system was good but ultimately did not have the flexibility and feature sets that we required."
Check the Story